News
Discover Simmons
Explore the latest news from Simmons as well as stories about leadership, science & technology, our faculty and more.
Or search all news stories for the topic of your choice.
The Latest News

Creating Impact at the 45th Annual Simmons Leadership Conference
The 2024 conference featured a roster of speakers exploring this year’s theme of “Creating Impact” in their personal and professional lives, and how those efforts ripple out to the people and communities around them.

Breaking Ground with Qualitative Research in Hospice Care
Stephanie Wladkowski ’14PhD was a clinical social worker in hospice care when policy changes impacted her clinical practice. In a search for answers, Wladkowski began her PhD in Social Work at Simmons. Her dissertation, “Dementia Caregivers and Live Discharge from Hospice: What Happens When Hospice Leaves?,” has inspired further research in the field.

Professor of Communications Bob White Featured in Oral History Collection of Artists During COVID-19
During the COVID-19 lockdown (2020–2021), local photographer and filmmaker Jerry Russo interviewed hundreds of artists about their experiences of isolation, including Professor of Communications Bob White. The University of Massachusetts Amherst has since archived this oral history collection.

Nathan Brewer ’10MSW ’18PhD on Protecting College Students
Nathan Brewer ’10MSW ’18PhD is Director of the Sexual Assault Response & Prevention Center (SARP) at Boston University (BU). After receiving his Master’s in Social Work from Simmons, he returned to the University to pursue his PhD in Social Work alongside his clinical practice. We spoke to Brewer about his experience in the program, and his current work at Boston University.

Nursing Student Receives Excellence in Nursing Practice Award from New England Regional Black Nurses Association
Samantha Normilus ’19BSN, ’26MSN has received the Excellent in Nursing Practice Award from the New England Regional Black Nurses Association, Inc. (NERBNA). A Dana-Farber Cancer Institute nurse who is pursuing the online MSN-FNP program at Simmons, Normilus spoke with us about being a NERBNA awardee, the rewards of oncology nursing, and the supportive community she found at Simmons.

Andrea London and Jessica London-Rand ’04MSW Ran the Boston Marathon to Memorialize Their Father
Knowing how significant running was to Professor Stephen London (1942–2022), his daughters Andrea London and Jessica London-Rand ’04MSW ran the 2023 Boston Marathon to honor his legacy, and continue to fundraise in his name. We spoke with them about their...

Discovering Purpose and Community through Art, Service, and Song
Arts Administration major Calla Savelson ’24 shares how she gained professional experience and build a community for herself during her time at Simmons.

Professor Gary Bailey Receives Lifetime Achievement Award from Massachusetts Commission on LGBTQ Youth
According to the Mass.gov press release, this event “was a testament to the unwavering commitment of all involved to create a more inclusive and supportive environment for young people of all gender identities and sexual orientations.”
Leadership in the News
Creating Impact at the 45th Annual Simmons Leadership Conference
The 2024 conference featured a roster of speakers exploring this year’s theme of “Creating Impact” in their personal and professional lives, and how those efforts ripple out to the people and communities around them.

Self-Curating the College Experience: Sojourn in Spain, Scientific Research, and Senior Care
Public Health major Abigail Bloom ’24 discusses her study abroad experience, the research projects she has participated in, and some of her favorite courses at Simmons.

Discovering an Empowering Atmosphere, Supportive Mentors, and Leadership Opportunities at Simmons
Neurobiology major Debora Edouard ’24 discusses her favorite moments at Simmons, her research, and her unique experience as a first-generation college student.

Reflecting on Community Service, Friendship, and Fun at Simmons
First-generation student Gia Elie ’24 has engaged in community service in the Boston area as part of the Alpha Kappa sorority. She has also been involved with the Black Student Organization and has completed two internships. She counts the friendships she has made at Simmons as one of her most transformative experiences.

Library and Information Science PhD Student Named Acting Director of IMLS
Cyndee Landrum, a student in the Simmons University Library and Information Science PhD, has been named Acting Director of the Institute of Museum and Library Services (IMLS).

Simmons Alum Kelly O’Connell Champions Women and Nonbinary Entrepreneurs
Since joining the Simmons University Alumnae/i Association Executive Board (AAEB), Kelly O’Connell ’99 has helped launch the Simmons Tuesday Tea Podcast, and co-hosted the Byond Balance event last November. On April 2, AAEB is hosting a special Simmons campus screening of “Show Her The Money,” a documentary that delves into the gender gap in venture capital funding with a focus on empowering women entrepreneurs.

Simmons Welcomes Passionate Leaders Project Scholars for Spring 2024
The Passionate Leaders Project (PLP) supports Simmons undergraduates by enriching their academic and professional interests beyond the boundaries of a conventional classroom. Students may request up to $4,000 to support their research, internships, and creative endeavors. This semester’s cohort comprises student-scholars producing original research on healthcare for seniors, fashion sustainability, and the intersection of the arts, social justice, and gender-expansive agency.

Dr. Ena Williams Champions Workplace Diversity in Dotson Bridge and Mentoring Program Lectureship Event
On February 29, the Dotson Bridge and Mentoring Program, directed by Associate Professor of Practice LaDonna Christian, hosted a Lectureship Event with Dr. Ena Williams. Her lecture, entitled, “Experiences of Racial and Ethnic Minority Nurses: Our Role in Advancing Workforce Diversity,” identified workplace biases and underscored the need for mentorship, racial equity, and organizational change.
STEM in the News

Debora Edouard ’24 and Kadijah McClean ’24 Open Simmons Chapter of the National Society of Black Women in Medicine
Established in 2017, the National Society of Black Women in Medicine is committed to increasing the recruitment and retention of Black women pursuing careers in the medical field. This academic year, Neurobiology major Debora Edouard ’24 and Biochemistry and Public Health minor Kadijah McClean ’24 co-founded the Simmons chapter of the Society.
Simmons Welcomes Passionate Leaders Project Scholars for Spring 2024
The Passionate Leaders Project (PLP) supports Simmons undergraduates by enriching their academic and professional interests beyond the boundaries of a conventional classroom. Students may request up to $4,000 to support their research, internships, and creative endeavors. This semester’s cohort comprises student-scholars producing original research on healthcare for seniors, fashion sustainability, and the intersection of the arts, social justice, and gender-expansive agency.

Professor Jennifer Roecklein-Canfield Selected as a 2024 Fellow of the American Society for Biochemistry and Molecular Biology
Jennifer Roecklein-Canfield, Professor of Chemistry and Physics at Simmons, is among the 2024 cohort of Fellows within the American Society for Biochemistry and Molecular Biology (ASBMB). She spoke with us about receiving this honor, advocating for women in STEM, and reimagining mentorship.
Associate Professor of Biology Eric Luth Co-Authors Scientific Article with Former Students
Neurobiologist Eric Luth recently co-authored a peer-reviewed article in the Journal of Toxicology and Environmental Health, Part A (October 2021) with several of his students: Celine Breton ’21, Kaitlyn Kessel ’23, Ariel Robinson ’19, and Kainat Altaf ’22. The piece traces developmental abnormalities among worm populations after exposure to environmental contaminants.

Honoring 50 Years of the Park Science Center and Celebrating a New Era at Simmons University
At the time it was built in the early 1970’s, the Park Science building served as a symbol of progress and achievement in women's-centered education. It challenged gender norms and societal expectations while promoting inclusivity and diversity in academia.

Dr. Stacey Pazar Huth ’87 Shares Family’s Multigenerational History with Simmons
Chemist and biomedical product developer Stacey Pazar Huth ’87 is a leading woman in medical diagnostics and research and development. Her connection to Simmons also involves her father, who helped build the campus, and her daughter, a current nursing major. We spoke with Huth about her Simmons journey, the gender bias in STEM, and her understanding of legacy.

Simmons Creates Paths to Engineering
Simmons University is officially partnered with Washington University in St. Louis in the Engineering 3+2 program, in addition to Columbia University. As part of this program, students complete three years of course work at Simmons, followed by two additional years at a partner institution, earning both a Bachelor of Science in Engineering and a Bachelor of Science from Simmons.

Eva Piernas' Journey from Simmons University to Infectious Disease Research ('23)
How Did Eva's Time at Simmons University Shape Her Path in Science? Eva Piernas, a recent 2023 alumni, reflected upon her journey at Simmons University, where she majored in Neuroscience on the neurobiology track and minored in Chemistry. As she...
Faculty in the News
Professor of Communications Bob White Featured in Oral History Collection of Artists During COVID-19
During the COVID-19 lockdown (2020–2021), local photographer and filmmaker Jerry Russo interviewed hundreds of artists about their experiences of isolation, including Professor of Communications Bob White. The University of Massachusetts Amherst has since archived this oral history collection.
Professor Gary Bailey Receives Lifetime Achievement Award from Massachusetts Commission on LGBTQ Youth
According to the Mass.gov press release, this event “was a testament to the unwavering commitment of all involved to create a more inclusive and supportive environment for young people of all gender identities and sexual orientations.”

Navigating the North Star: Assistant Professor Tatiana M.F. Cruz Receives Diversity, Equity, Inclusion and Justice Award
The American Council on Education Women’s Network Massachusetts has recognized Tatiana M.F. Cruz, Assistant Professor and Interdisciplinary Program Director of Africana Studies and Women’s and Gender Studies, and her collaborator Dr. Kamille Gentles-Peart (Roger Williams University) for co-founding and directing the North Star Collective, a group of colleges and universities in New England that are committed to faculty racial equity.

Professor Suzanne Leonard Discusses “Sex and the City’s” Toxic Masculinity in Los Angeles Times
“Audiences [today] are much more aware of the dangers of toxic masculinity, and that doesn't read as sexy anymore. I think you have more sophisticated feminist viewers,” says Leonard.
Professor Jennifer Roecklein-Canfield Selected as a 2024 Fellow of the American Society for Biochemistry and Molecular Biology
Jennifer Roecklein-Canfield, Professor of Chemistry and Physics at Simmons, is among the 2024 cohort of Fellows within the American Society for Biochemistry and Molecular Biology (ASBMB). She spoke with us about receiving this honor, advocating for women in STEM, and reimagining mentorship.
Associate Professor of Social Work Olivia Montgomery Promotes Fat Liberation
In December of 2023, Simmons School of Social Work Associate Professor Olivia Montgomery offered virtual testimony in support of a bill prohibiting body size discrimination. In a presentation to the Simmons community in February, Montgomery offered an introduction to Fat Liberation in Social Work, examining the root causes of anti-fatness and its widespread consequences.

School of Social Work Dean Among Most Impactful Contributors
School of Social Work Dean Michael LaSala was included in the 100 Most Impactful Global Contributors to Social Work Publications, a list published by Sage Journals.
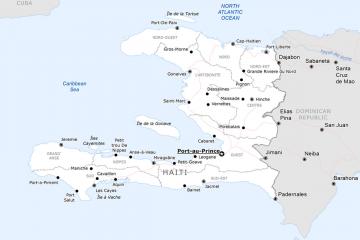
Assistant Professor Patrick Sylvain Offers Insights into Crisis in Haiti
After armed groups overran Port-au-Prince, thereby displacing thousands of residents and hindering access to food, Haiti’s government declared a state of emergency on March 4, 2024. According to Sylvain, Haiti must cultivate strong leadership to overcome the current crisis.
Connect with Simmons
Media Inquiries
Members of the press should feel free to reach out with questions regarding any aspect of the University, including commentary from faculty experts on the news of the day.
One Simmons
As the University changes to meet the evolving needs of our students, we are ensuring that our physical space also meets those needs.
Submit Your News Story Idea
If a faculty member, student, or alum has published a paper, won an award, started a notable job or completed an important project, we want to know about it!
Simmons Magazine
Through news and feature stories, the Simmons Magazine highlights the inspiring ways members of our community are making a difference in their career fields, communities, and the wider world.
Laura Wareck
Associate Vice President of University Communications